
1. 논리적 데이터베이스 모델?
- 논리적 모델은 비즈니스 정보의 논리적 구조와 구성을 캡처할 수 있습니다.
즉, 핵심 엔터티와 키 엔터티를 식별하고 모델링하여 데이터베이스 구조를 모델링한다.
2. EARTH에 대한 설명?
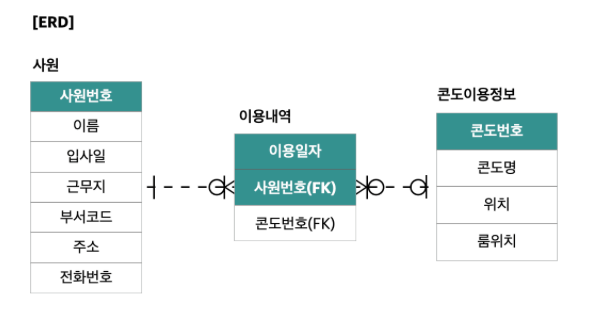
- 사용 내역 엔터티에서 “사용일 + 사원번호가 기본키(PK)이기 때문에 같은 날 여러 콘도를 사용할 수 없습니다.”
- 직원, 사용내역(1:M) -> 직원 1명은 사용내역이 있을 수도 있고 없을 수도 있습니다.
- 콘도 점유 정보, 점유 세부 정보(1:0 또는 1:1): M -> 콘도 점유 정보가 있을 수도 있고 없을 수도 있으며, 콘도 점유 정보가 점유 세부 정보에 있을 수도 있고 없을 수도 있습니다.
3. 관계를 정상화하는 목적은 무엇입니까?
- 정규화는 기능적 종속성에 따라 테이블을 분해하여 데이터 중복성을 제거하여 모델 독립성을 향상시키는 프로세스입니다.
- 정규화가 수행되지 않으면 삽입, 삭제 및 수정에 문제가 발생합니다.
- 데이터베이스 보안과 관련된 것은 보기입니다.
4. 엔터티, 관계, 속성?
- 엔티티의 특성
- 식별자: 엔터티에는 고유한 식별자가 있어야 합니다.
- 인스턴스 세트: 2개 이상의 인스턴스가 있어야 합니다.
- 속성: 엔티티에는 속성이 있어야 합니다.
- 관계: 엔터티는 다른 엔터티와 적어도 하나의 관계를 가져야 합니다. 엔터티의 관계 -> 집합 간의 관계.
- 작업: 엔터티는 작업에서 관리해야 하는 컬렉션입니다.
- 엔터티 유형
- 독립 개체(Kernel Entity, Master Entity): 실세계에 존재하는 개체 B. 사람, 사물 또는 장소.
- 트랜잭션 개체: 트랜잭션이 진행되는 동안 발생하는 개체입니다.
- 종속 엔터티: 주로 1차 정규화로 인해 관련 중앙 엔터티에서 분리된 엔터티입니다.
- Interaction Entity: (M:M) 관계를 해소할 목적으로 생성된 개체.
- 유형, 무형 엔티티 유형
- Tangible Entity: 업무에서 비롯되어 지속적으로 사용되는 개체.
- 개념 엔터티: 개념적으로 사용되는 엔터티로, 물질 엔터티는 물리적 형태를 가지며 개념적 엔터티는 물리적 형태가 없습니다.
- 인시던트 엔터티: 비즈니스 프로세스 실행 중에 생성된 엔터티입니다.
- 발생 시간별 엔티티 유형
- 기본 유닛: 다른 유닛의 영향을 받지 않고 독립적으로 생성되는 유닛으로 키 유닛이라고도 합니다.
- 주요 개체: 기본 개체와 행동 개체 사이의 개체, 기본 개체에서 발생하고 행동 개체를 생성하는 개체입니다.
- Active Entity: 두 개 이상의 개체로 구성된 개체로 정보가 지속적으로 추가되고 변경되는 개체입니다.
5. 지구에 대한 설명?
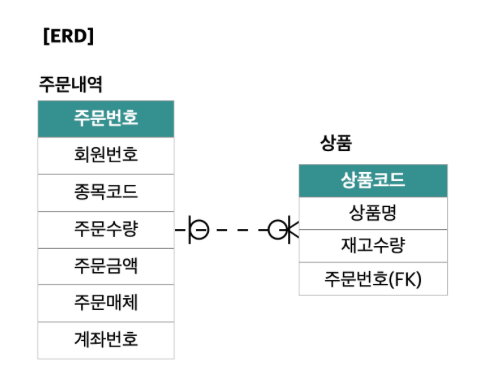
- 제품에는 하나 이상의 주문이 있을 수도 있고 없을 수도 있습니다.
- ERD 동일시 관계에서 O는 “있을 수도 있고 없을 수도 있다”의 의미를 갖는다.
6. 올바른 ERD 표기법은 무엇입니까?
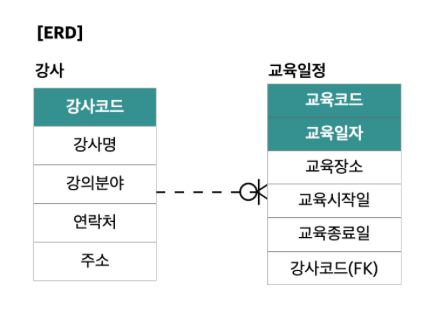
- ERD 표기법 하에서 IE 표기법은 관계의 1:N 관계에서 N측에 새로운 바닥글을 표시하고, 선택하고, 필수 참여 관계에서 선택적 참여(또는)를 위해 O를 선택하고, 참여를 요구합니다 | 표시된
7. 각 주식의 특징은 무엇입니까?

- 동일한 기입일로 동일한 노트가 생성되기 때문에 끝에 동일한 값이 추가되어 최소값이 아니므로 잘못된 모델링입니다.
- 식별자의 속성
- 고유성: 엔터티 내의 모든 인스턴스는 자산 식별자로 고유하게 식별되어야 합니다.
- 미니멀리즘: 스톡 단조를 구성하는 속성의 수는 고유성을 만족하는 최소 수여야 합니다.
- 불변성: 주어진 자산 식별자의 값은 자주 변경되어서는 안 됩니다.
- 존재: 보유 식별자가 지정된 경우 값을 입력해야 합니다(NULL일 필요는 없음).
- 식별자의 분류
- 묘사
– 인벤토리별: 엔티티 내 각 라인을 구분할 수 있는 구분자이자 다른 엔티티와의 참조 관계를 연결할 수 있는 식별자입니다.
– 보조식별자 : 개체 내에서 각 줄을 구분할 수 있는 구분자이나 대표성이 없어 참조관계를 맺을 수 없다. - 스스로 만든
– 내부 식별자: 엔터티 내부에서 스스로 생성하는 식별자.
– 외부식별자 : 다른 개체와의 관계를 통해 다른 개체로부터 획득한 식별자이다. - 속성 수
– 고유 식별자: 속성으로 구성된 식별자.
– 복합 식별자: 둘 이상의 속성으로 구성된 식별자. - 대리자
– 필수 식별자: 작업(비즈니스)에서 말하는 식별자입니다.
– 인공식별자 : 업무용으로 생성된 것이 아니라 원래 식별자가 복잡한 구조를 가지고 있어 인위적으로 생성한 것입니다.
- 묘사
8. SQL 문의 결과는?
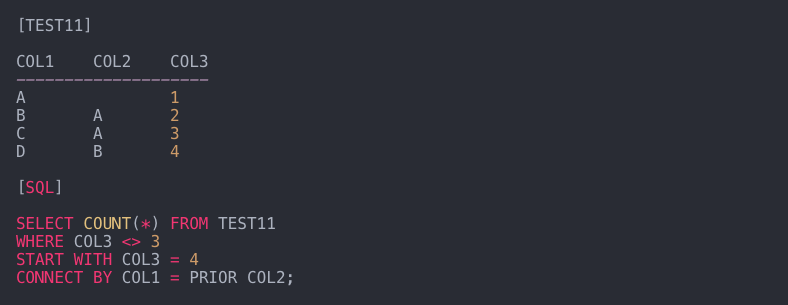
- CONNECT BY -> 계층적 쿼리는 데이터를 선택하고 계층적 순서로 반환하는 데 사용됩니다.
- 현재 줄과 다른 줄은 PRIOR 키워드로 구별됩니다.
PRIOR는 부모행을 말하며 위의 SQL 문에서 “이전 행의 COL2 값이 현재 행의 COL1 값인 행을 모두 찾는다”는 의미이다. - WHERE 절의 COL3이 3인 행 제외 -> COL3을 4로 시작 -> CONNECT BY COL1 = PRIOR COL2
COL1 COL2 COL3
DB4
제로 1
BA 2 총 3개가 있습니다.
9. JOIN에 대한 설명?
- 중첩 루프 조인
- 좁은 지역에 좋습니다.
- Glass는 순차적으로 처리되고 랜덤 액세스를 위해 정렬됩니다.
- 조인을 위한 인덱스는 구동 테이블에 생성되어야 합니다.
- 실행 속도 = 이전 테이블의 크기 * 다음 테이블에 대한 액세스 수
- 중첩 인덱스 루프 조인, 단일 루프 조인
- 구동 테이블의 조인 속성에 인덱스가 존재할 때 사용합니다.
- 다음 테이블의 인덱스 접근 구조를 이용하여 앞선 테이블의 각 레코드를 직접 조회한 후 조인하는 방식이다.
- 병합 연결 정렬
- 정렬 병합 조인은 테이블에 인덱스가 없을 때 수행됩니다.
- 테이블을 정렬한 후 정렬된 테이블을 병합하여 조인을 수행합니다.
- 조인 체인의 비교 연산자가 범위 연산(>, <)이면 중첩 루프 조인보다 유리하다.
- 이는 두 결과 집합의 크기가 매우 다른 경우 비효율적입니다.
- 해시 조인
- 해시 함수를 사용하여 두 테이블의 데이터를 결합하는 조인 방법입니다.
- 중첩 루프 조인 및 정렬 병합 조인의 문제를 해결합니다.
- 많은 양의 데이터를 처리하려면 상당히 큰 해시 범위가 필요하므로 과도한 메모리 사용으로 인한 오버헤드가 발생할 가능성이 있습니다.
10. SQL 명령?
- DDL(데이터 정의 언어): CREATE, DROP, MODIFY(ORACLE), ALTER(SQL SERVER), RENAME, TRUNCATE
- DML(데이터 조작 언어): SELECT, INSERT, DELETE, UPDATE
- DCL(데이터 제어 언어): GRANT, REVOKE
- TCL(트랜잭션 제어 언어): COMMIT, ROLLBACK, SAVE POINT
11. 다음 중 SQL 문의 공백을 채우는 것은 무엇입니까?
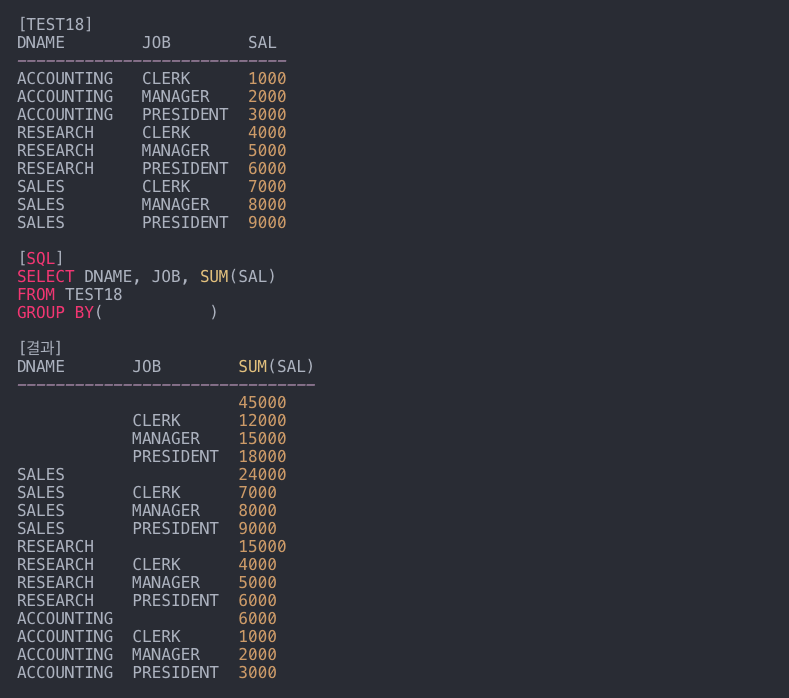
- DNAME별 소계, JOB -> DNAME별 소계 -> JOB별 소계 -> 합계 집계
- 롤업
- 하위 그룹 간의 총계 및 소계를 계산하는 ROLLUP 함수
- 롤업 후 그룹화(DEPTNO)
-> DEPTNO 총계(소계), 총계 조회
- 주사위
- CUBE는 제시된 열에 대해 결합할 수 있는 모든 집계를 계산합니다.
- 데이터를 다양한 방식으로 분석할 수 있도록 다차원 집계를 제공합니다.
- GROUP BY CUBE(DEPTNO, JOB)
-> DEPTNO 합계, JOB 합계, DEPTNO & JOB 합계, 합계 합계 검색
-> 가능한 모든 조합이 결합됩니다(시스템 부하의 단점).
- 그룹핑 세트
- 원하는 부분의 소계만 추출하여 계산할 수 있는 GROUPING SETS 기능
12.PL/SQL?
- PL/SQL은 PL/SQL에서 테이블을 생성할 수 있는 절차적 언어입니다.
- PL/SQL에서 테이블을 생성하는 이유는 짧은 기간 동안 임시 테이블로 사용되기 때문입니다.
- PL/SQL에서 조건문은 IF ~ THEN ~ ELSE IF ~ END IF 및 CASE ~ WHEN을 사용합니다.
- PL/SQL에서 NAME이라는 변수에 ‘aaa’를 할당할 때 “:=”를 사용합니다.
13. 인덱스 생성 구문?
- 인덱스 생성/삭제 구문
- 생성: CREATE INDEX 인덱스 이름 ON 테이블 이름(속성 이름 등)
- 삭제: DROP INDEX 인덱스 이름 ON 테이블 이름
- 인덱스 수정
- 수정: 인덱스를 삭제한 후 인덱스 재구축 방법을 사용해야 합니다.
- 색인 검색
- SELECT 테이블명, 인덱스명, 컬럼명
ALL_IND_COLUMNS에서
WHERE TABLE_NAME = ‘테이블 이름’
- SELECT 테이블명, 인덱스명, 컬럼명
14. 직원이 없는 부서(DEPTNO)를 검색하는 쿼리를 작성하는 경우 가장 먼 곳은 어디입니까?
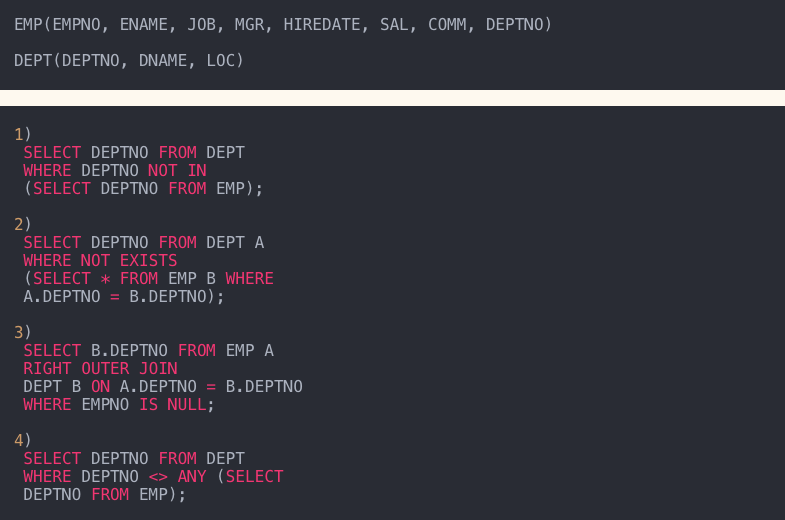
- <>(같지 않음), ANY(여러 비교 값 중 하나라도 충족되면 TRUE).
- EMP 테이블에 DEPTNO(10, 20, 30)이 있고 DEPT 테이블에 DEPTNO(10, 20, 30, 40)가 있다고 가정합니다.
- DEPTNO가 없는 경우(EMP에서 DEPTNO 선택);
-> 테이블 DEPT의 DEPTNO에서 10, 20, 30을 제외하여 출력한다. - 존재하지 않는 경우(A.DEPTNO = B.DEPTNO인 경우 EMP B에서 선택 *);
-> DEPT 테이블에서 DEPTNO에 대해 10, 20, 30 이외의 값을 출력한다. - RIGHT OUTER JOIN DEPT B ON A.DEPTNO = B.DEPTNO 여기서 EMPNO는 NULL입니다.
-> DEPT 테이블의 전체 DEPTNO 및 DEPT 테이블 DEPTNO와 동일한 EMP 테이블 DEPTNO 아래에서 EMP 테이블의 EMPNO 값이 NULL인 DEPT 테이블의 DEPTNO가 출력된다. - WHERE DEPTNO <> ANY(EMP에서 DEPTNO 선택);
-> 테이블의 DEPTNO 아래 DEPTNO가 ANY의 비교값과 같지 않으면 DEPT가 출력된다.
- DEPTNO가 없는 경우(EMP에서 DEPTNO 선택);
15. 인덱스를 이용하여 검색 속도를 향상시킬 수 있는 쿼리로 적절하지 않은 것은?
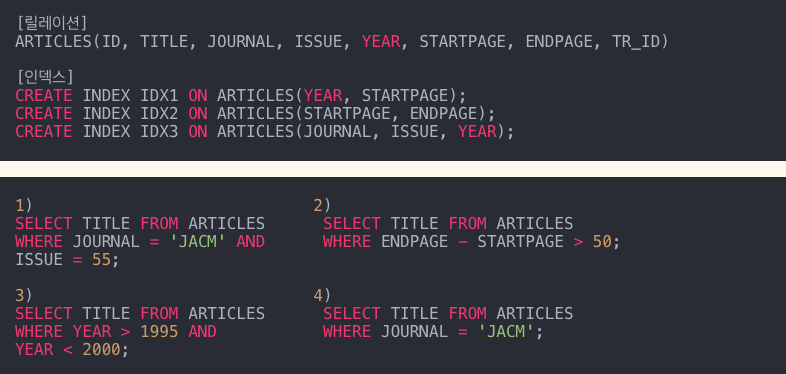
- 인덱스에 대해 연산을 수행하면 인덱스가 변환되므로 인덱스를 사용할 수 없습니다.
따라서 2단계의 ‘-‘ 연산을 수행할 수 없습니다.
16. 분산 데이터베이스?
- 분산 데이터베이스의 특징
- 분산 데이터베이스는 여러 데이터베이스를 병렬로 실행하여 성능을 향상시킵니다.
- 분산 데이터베이스는 여러 데이터베이스를 네트워크로 물리적으로 분리한 데이터베이스입니다.
- 분산 데이터베이스의 장점
- 데이터베이스의 안정성과 가용성이 높습니다.
- 분산 데이터베이스가 병렬 처리를 하기 때문에 빠른 응답이 가능합니다.
- 분산 데이터베이스를 추가하여 시스템 용량을 쉽게 확장할 수 있습니다.
- 분산 데이터베이스의 단점
- 데이터베이스가 여러 네트워크로 분리되어 있기 때문에 관리 및 제어가 어렵습니다.
- 보안 관리가 어렵습니다.
- 데이터 무결성 관리가 어렵습니다.
- 데이터베이스 디자인은 복잡합니다.
17. 실행계획은?
- 실행 계획이란 무엇입니까?
SQL을 실행하는 절차 및 방법을 말합니다. - 데이터베이스에서 SQL이 실행될 때 실행 절차와 방법이 표현되어 DBA에게 전달된다.
- SQL 개발자는 SQL을 작성하고 실행할 때 SQL 실행 방법을 계획합니다. 즉, SQL 실행 계획을 생성한 후 SQL을 실행합니다.
- 옵티마이저는 SQL 실행 계획(RULE, COST)을 생성하고 SQL을 실행하는 데이터베이스 관리 시스템 소프트웨어입니다.
18. 지수에 대한 설명?
- 분할된 인덱스를 통해 파티션 키에 인덱스를 생성할 수 있으며, 파티션 키에 생성된 인덱스를 GLOBAL 인덱스라고 합니다.
- 파티셔닝은 일정한 기준에 따라 나누는 것을 의미합니다.
- 인덱스에는 순차 인덱스, 복합 인덱스, 비트맵 인덱스, 클러스터 인덱스 및 해시 인덱스가 포함됩니다.
- 인덱스 수가 증가할수록 입력, 삭제 및 수정 속도가 느려질 수 있습니다.
- 인덱스는 VARCHAR, CHAR, DATE 및 NUMBER에서 생성할 수 있습니다.
19. 운영자 우선순위?
- 산술 연산자(*, /, +, -)
- 연결 연산자(||)
- 비교 연산자(<, >, <=, =><>, =)
- NULL, AS, IN
- 사이
- NOT 연산자
- AND 연산자
- OR 연산자
20. SELF JOIN은 어떻습니까?
- SELF JOIN은 동일한 테이블에 대해 발생하는 조인을 나타내며 동일한 테이블 이름이 FROM 절에 두 번 이상 나타납니다.
SELF JOIN은 동일한 테이블을 여러 번 사용하므로 FROM 절에 별칭을 사용해야 합니다.
21. SQL 문의 실행 결과는?
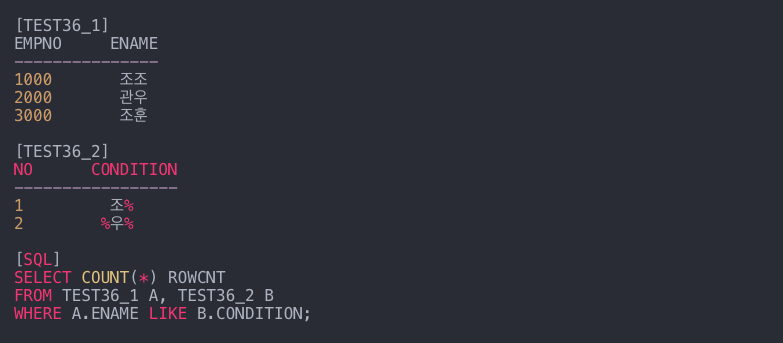
- SELECT * FROM(테이블 이름) WHERE LIKE(조건)
- SELECT 컬럼명 FROM 테이블 WHERE 컬럼명 LIKE ‘A%’
-> A로 시작하는 문자 찾기 - SELECT 컬럼명 FROM 테이블 WHERE 컬럼명 LIKE ‘%A’
-> A로 끝나는 문자 찾기 - SELECT 열 이름 FROM 테이블 WHERE 열 이름 LIKE ‘%A%’
-> A가 포함된 문자 찾기 - SELECT 열 이름 FROM 테이블 WHERE 열 이름 LIKE ‘A_’
-> A로 시작하는 두 글자 문자 찾기 - SELECT 열 이름 FROM 테이블 WHERE 열 이름 LIKE ‘(^A)’
-> 첫 번째 문자가 ‘A’가 아닌 모든 문자열 찾기 - SELECT 열 이름 FROM 테이블 WHERE 열 이름 LIKE ‘(ABC)’
SELECT 열 이름 FROM 테이블 WHERE 열 이름 LIKE ‘(AC)’
-> 첫 번째 문자가 ‘A’, ‘B’, ‘C’인 문자열 찾기
22. SQL 문의 결과는?
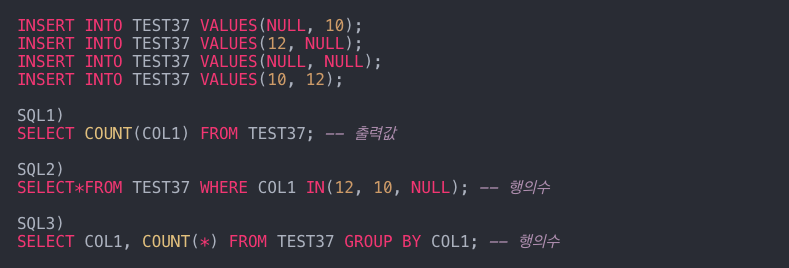
- 계산하기
- -> 총 행 수는 반환되는 경우 NULL을 포함합니다. 개수(COL1) ->
- 열 이름을 지정할 때 NULL을 포함하지 마십시오.
- WHERE COL1 IN(12, 10, NULL) -> 12, 10을 포함하고 NULL을 포함하지 않는 COL1을 찾습니다.
- GROUP BY COL1 -> NULL, 12, 10은 3개로 그룹화된다.
그래서 2, 2, 3.
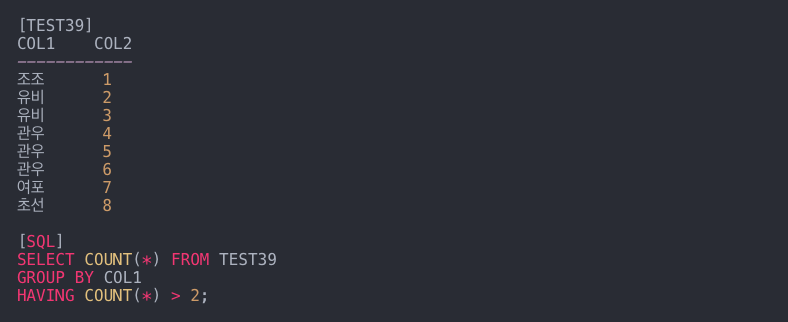
- 23. SQL 문의 결과는?
- GROUP BY COL1 -> 조조 1개, 유비 2개, 관우 3개, 루푸 1개, 조선 1개
계산해야
- > 2이므로 2보다 큰 수는 3입니다.
- 24. NUMERIC(숫자)을 입력하시겠습니까?
- CHAR(문자형): 고정 길이 문자열을 의미합니다.
- INT(정수형): 소수점이 없는 정수.
- DOUBLE(실수형): 8바이트 실수형
FLOAT(실수형): 4바이트 실수형
- DECIMAL : 소수점을 더 정확하게 표현합니다.
- 25. SQL 문의 실행 순서는?
- FROM 절에서 테이블 목록을 가져옵니다.
- WHERE 절의 검색 조건과 일치하지 않는 행을 제외합니다.
- GROUP BY 절에 지정된 행의 값을 그룹화합니다.
- HAVING 절은 GROUP BY 절로 그룹화된 데이터에 대한 조건을 정의합니다.
SELECT 절에 지정된 열 값을 검색합니다.
OPDER BY 절에 지정된 컬럼 값을 기준으로 정렬하여 반환합니다.